Indexing and Aggregation Pipeline
Aggregation Framework
- another way to query data in MongoDB
- everything that can be done with the query language can also be done with the aggregation framework
- new ways to work with data like group, compute, reshape, etc.
Syntax
Find all documents that have Wifi as one of the amenities. Only include price and address in the resulting cursor:
// with MQL
db.listingsAndReviews.find({ "amenities": "Wifi" },
{ "price": 1, "address": 1, "_id": 0 }).pretty()
// with the aggregation framework
db.listingsAndReviews.aggregate([
{ "$match": { "amenities": "Wifi" } },
{ "$project": { "price": 1,
"address": 1,
"_id": 0 }}]).pretty()
With the aggregation framework we can build pipelines:

Note: It matters in which order the different pipeline stages are since each pipeline stage uses the results of the preceding stage.
$group operator


Examples
Project only the address field value for each document, then group all documents into one document per address.country value:
db.listingsAndReviews.aggregate([ { "$project": { "address": 1, "_id": 0 }},
{ "$group": { "_id": "$address.country" }}])
Result:
{ _id: 'Turkey' }
{ _id: 'Spain' }
{ _id: 'Portugal' }
{ _id: 'Hong Kong' }
{ _id: 'China' }
{ _id: 'United States' }
{ _id: 'Australia' }
{ _id: 'Canada' }
{ _id: 'Brazil' }
Project only the address field value for each document, then group all documents into one document per address.country value, and count one for each document in each group:
db.listingsAndReviews.aggregate([
{ "$project": { "address": 1, "_id": 0 }},
{ "$group": { "_id": "$address.country",
"count": { "$sum": 1 } } }
])
Result:
{ _id: 'United States', count: 1222 }
{ _id: 'Hong Kong', count: 600 }
{ _id: 'Turkey', count: 661 }
{ _id: 'Spain', count: 633 }
{ _id: 'Brazil', count: 606 }
{ _id: 'Portugal', count: 555 }
{ _id: 'Canada', count: 649 }
{ _id: 'China', count: 19 }
{ _id: 'Australia', count: 610 }
Lab: Aggregation Framework
What room types are present in the sample_airbnb.listingsAndReviews collection?
Query:
db.listingsAndReviews.aggregate([ { "$group": { "_id": "$room_type" } }])
Result:
{ _id: 'Entire home/apt' }
{ _id: 'Private room' }
{ _id: 'Shared room' }
$sort and $limit operator
$sort Syntax:
// 1: increasing sort, -1: decreasing sort
db.zips.find().sort({ "pop": 1 })
$limit Syntax:
// only return 10 results of the resulting sort cursor
db.zips.find().sort({ "pop": -1 }).limit(10)
Indexes
- Indexes are special data structures that store a small portion of the collection's data set in an easy to traverse form
- Without indexes, MongoDB must perform a collection scan, i.e. scan every document in a collection, to select those documents that match the query statement
- Indexes therefore make queries more efficient
- They are one of the most impactful ways to improve query performance
When to index
- Support often used queries
- For example if you often use a specific field for filtering and aggregation it is useful to create an index for this field
Create an index
// Creates an index in increasing order
// It doesn't really matter whether the index was created in increasing or decreasing order when it is a simple single-field index.
db.trips.createIndex({ "birth year": 1 })
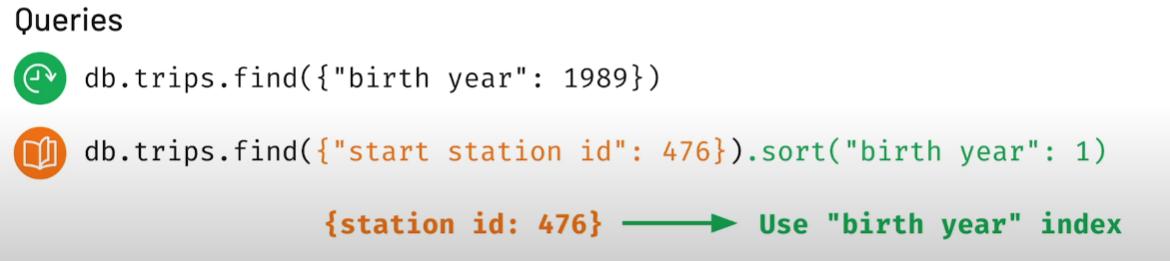
First query can use the index, second query needs to scan full collection for the filter but can use the index for the sort.
Compound Index
- MongoDB also supports user-defined indexes on multiple fields, i.e. compound indexes
- The order of fields listed in a compound index has significance. For instance, if a compound index consists of
{ userid: 1, score: -1 }, the index sorts first by userid and then, within each userid value, sorts by score - For compound indexes and sort operations, the sort order (i.e. ascending or descending) of the index keys can determine whether the index can support a sort operation

Helps with the query at the bottom since the documents are indexed by the station id and already sorted (indexed) by the birth year.
Upsert - Update or Insert
Definition: Upsert will update if a matching document exists otherwise it will insert a new document
Everything in MQL that is used to locate a document in a collection can also be used to modify this document:
db.collection.updateOne({<query to locate>}, {<update>})
Upsert is a hybrid of update and insert, it should only be used when it is needed:
// upsert is by default false
db.collection.updateOne({<query>},{<update>},{"upsert": true})
Quiz
How does the upsert option work?
Claim: It is used with the update operator, and needs to have its value specified every time that the update operator is called.
Answer: This is incorrect. The upsert option only needs its value specified if you want to change the default false setting to true.
Claim: By default upsert is set to false.
Answer: This is correct. If the upsert option is not specified, then it will have the value of false by default.
Claim: When upsert is set to true and the query predicate returns an empty cursor, the update operation creates a new document using the directive from the query predicate and the update predicate.
Answer: This is correct. When upsert is set to true it can perform an insert if the query predicate doesn't return a matching document.
Claim: When upsert is set to false and the query predicate returns an empty cursor then there will be no updated documents as a result of this operation.
Answer: This is correct. When upsert is set to false an update will happen only when the query predicate is matched with a document from the collection.