Pagination
Often, sets of data are too large to pass them directly to the consumer of our service. Pagination solves this problem by giving the consumer the ability to fetch a set in chunks. The current landscape of the pagination in GraphQL is hugely influenced by the Relay spec for Connections.
Connections vs Offset
GraphQL connections use cursor based pagination which is very well suited for large data sets as compared to offset based pagination. Offset pagination has drawbacks:
- If items are being written to the dataset at a high frequency, the page window becomes unreliable, potentially skipping or returning duplicate results.
- Using
LIMIT <count> OFFSET <offset>doesn’t scale well for large datasets. As the offset increases the farther you go within the dataset, the database still has to read up to offset + count rows from disk, before discarding the offset and only returning count rows
Offset problem visualized
We get some paginated data with our first request:

Before we can request the next page, the data set changes and we get a shifted result:

Connections approach
Connections solve this problem by using a cursor based pagination. Instead of using an offset, we use a cursor to fetch the next page. The cursor is a pointer to a specific item in the data set. The cursor is opaque to the client and can be anything that can be sorted. For example, it could be a date, a unique ID, or a pointer to an object in a database.
The spec outlines the following components:
- connection: a wrapper for details on a list of data you’re paginating through. A connection has two fields: edges and pageInfo.
- edges: a list of edge types.
- edge: a wrapper around the object being returned in the list. An edge type has two fields: node and cursor.
- node: this is the actual object, for example, user details.
- cursor: this is a string field that is used to identify a specific edge.
- pageInfo: contains two fields hasPreviousPage and hasNextPage which can be used to determine whether or not you need to request another set of results.
While the above might seem verbose, it allows the server to implement a robust pagination scheme:
- Returning a list of edge wrappers, each with a cursor, enables the client to paginate forwards and backwards from any point within the result set.
- The pageInfo details let the client clearly know if there is a previous or next page to fetch.
- Requiring the cursor to be a string value promotes the use of an opaque cursor value. The javascript implementation of the Relay spec for instance uses Base64 encoded IDs as cursor values. This discourages the client from implying what value goes in this field and gives the server the ability to encode additional information within the cursor.
With this setup we can request the next page without having to worry about the data set changing:
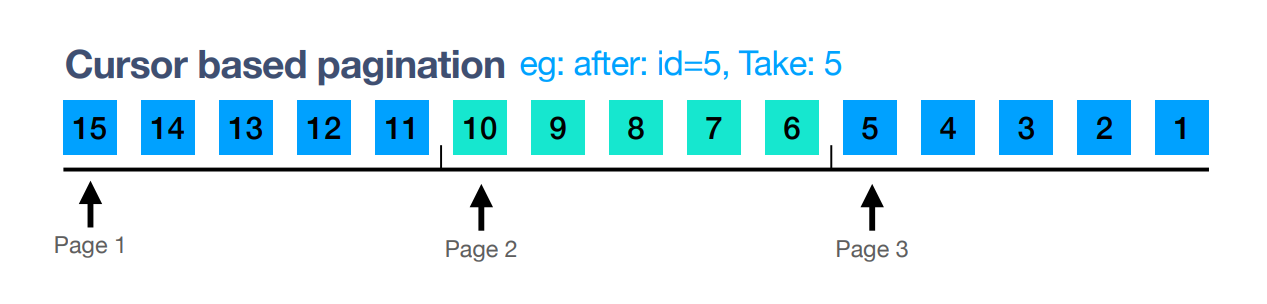
Second request:
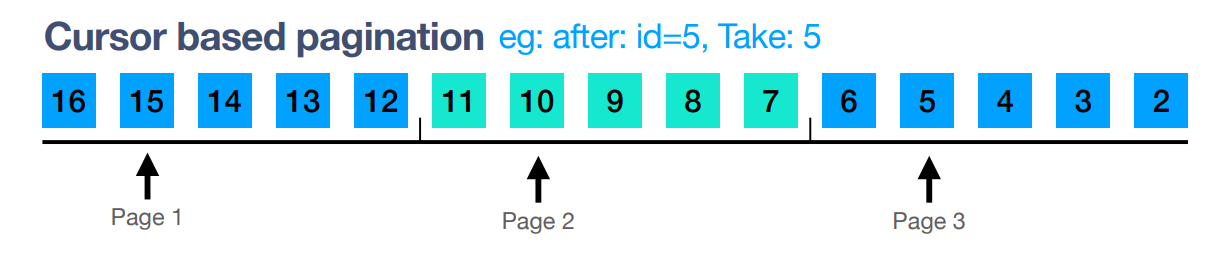
An Example (Relay spec)
There are three important points to understand:
- Edges themselves have properties — for example, in a list of your friends, the date when you friended that person is a property of the edge between you, rather than of the other person per se. We handle this by creating nodes that represent the edges.
- The list itself has properties, such as whether or not there is a next page available. We handle this with a node that represent the list itself as well as one for the current page.
- Pagination is done by cursors — opaque symbols that point to the next page of results — rather than offsets.
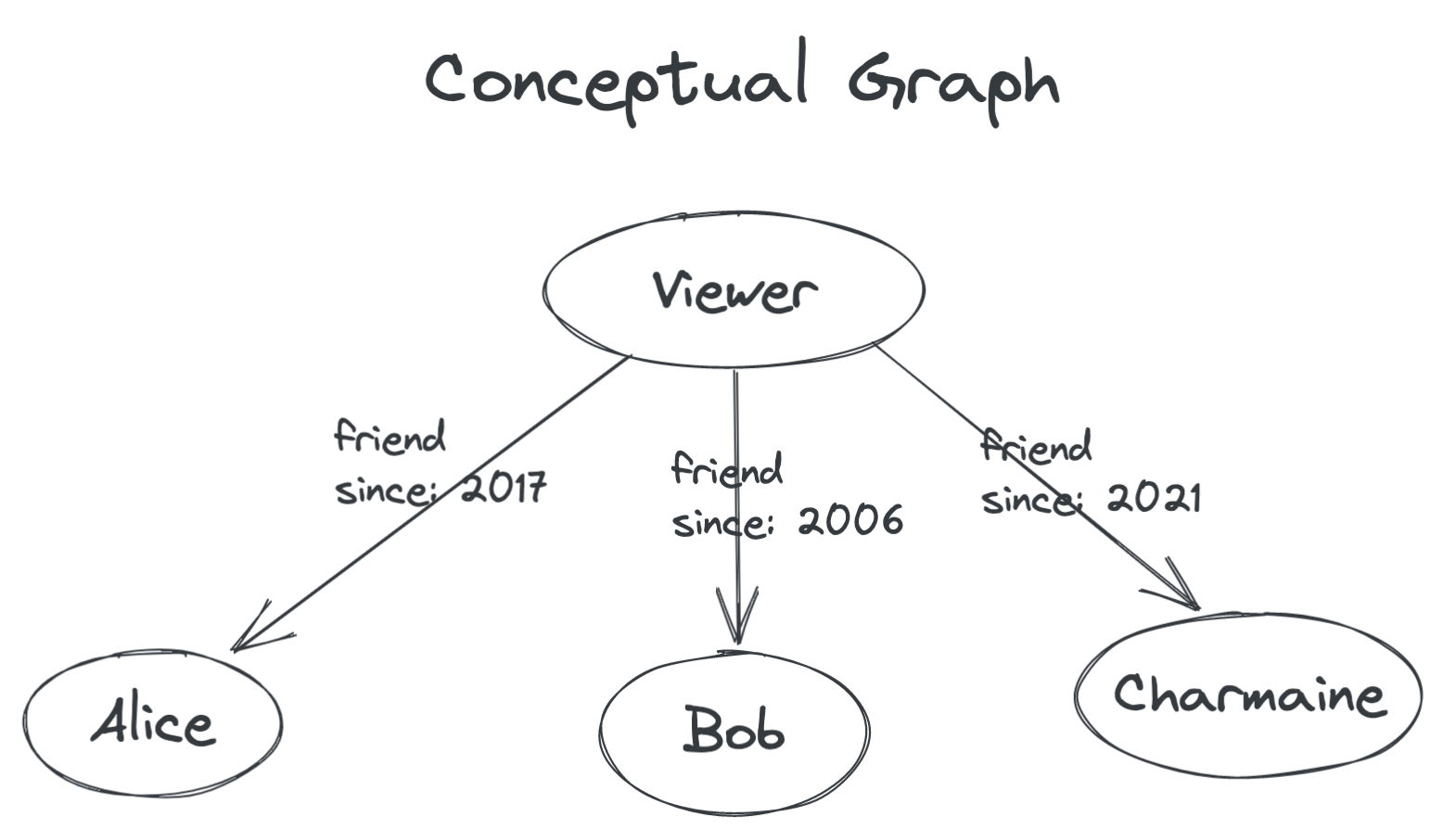
Imagine we want to show a list of the user’s friends. At a high level, we imagine a graph where the viewer and their friends are each nodes. From the viewer to each friend node is an edge, and the edge itself has properties:
In GraphQL, only nodes can have properties, not edges. So the first thing we’ll do is represent the conceptual edge from you to your friend with its very own node:
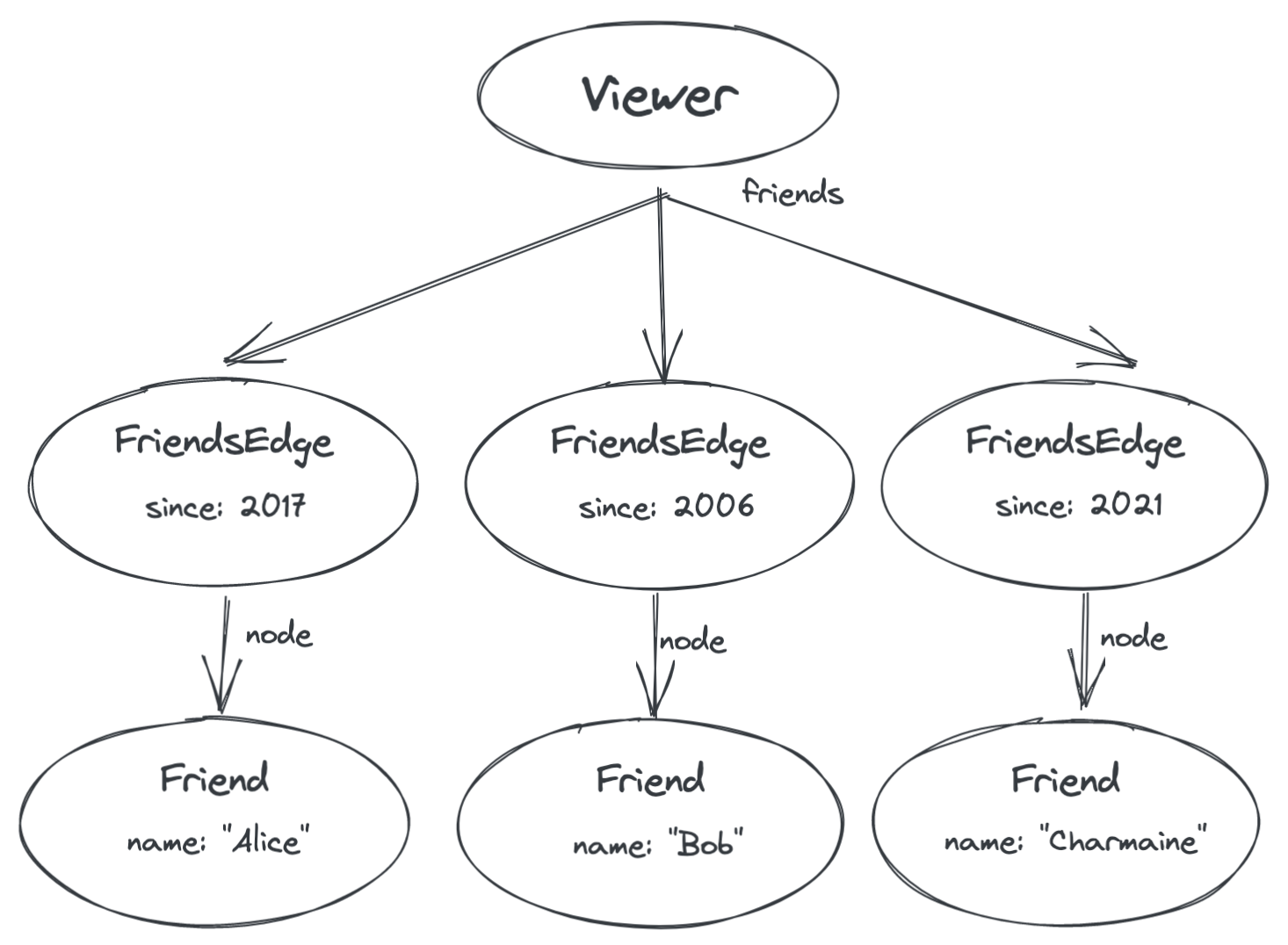
Now the properties of the edge are represented by a new type of node called a FriendsEdge. The GraphQL to query this would like this:
fragment FriendsFragment1 on Viewer {
friends {
since // a property of the edge
node {
name // a property of the friend itself
}
}
}
How pagination is modeled
Now we have a good place in the GraphQL schema to put edge-specific information such as the date when the edge was created (that is, the date you friended that person). Now consider what we would need to model in our schema in order to support pagination and infinite scrolling:
- The client must be able to specify how large of a page it wants.
- The client must be informed as to whether any more pages are available, so that it can enable or disable the ‘next page’ button (or, for infinite scrolling, can stop making further requests).
- The client must be able to ask for the next page after the one it already has.
Specifying the page size is done with field arguments. In other words, instead of just friends the query will say friends(first: 3), passing the page size an argument to the friends field.
For the server to say whether there is a next page or not, we need to introduce a node in the graph that has information about the list of friends itself, just like we are introducing a node for each edge to store information about the edge itself. This new node is called a Connection.
The Connection node represents the connection itself between you and your friends:
- e.g. it could have a totalCount field that says how many friends you have
- It always has two fields which represent the current page:
- The
pageInfofield with metadata about the current page, such as whether there is another page available - An
edgesfield that points to the edges we saw before
- The
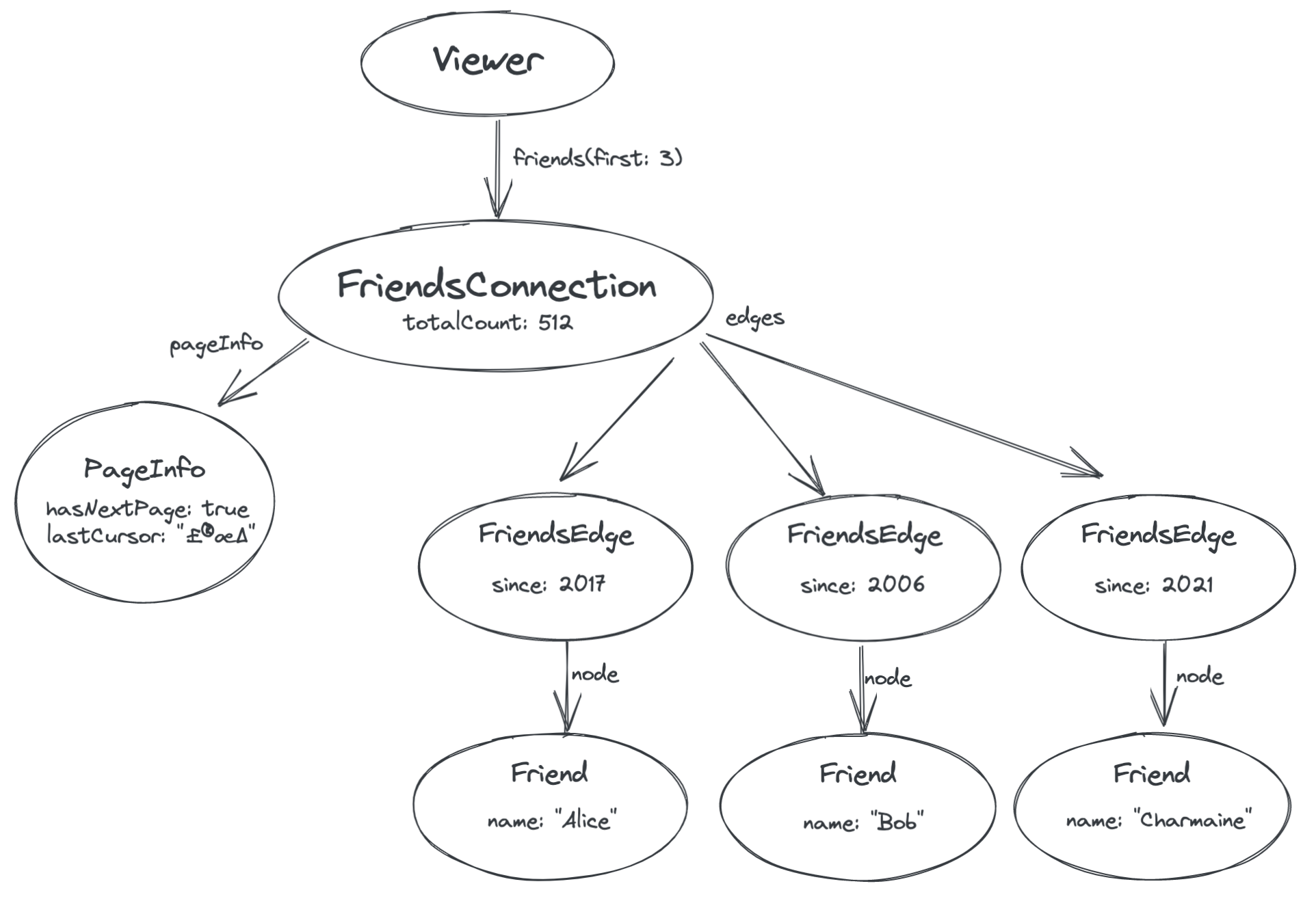
Finally, we need a way to request the next page of results. You’ll notice in the above diagram that the PageInfo node has a field called lastCursor. This is an opaque token provided by the server that represents the position in the list of the last edge that we were given (the friend “Charmaine”). We can then pass this cursor back to the server in order to retrieve the next page.
By passing the lastCursor value back to the server as an argument to the friends field, we can ask the server for friends that are after the ones we’ve already retrieved:
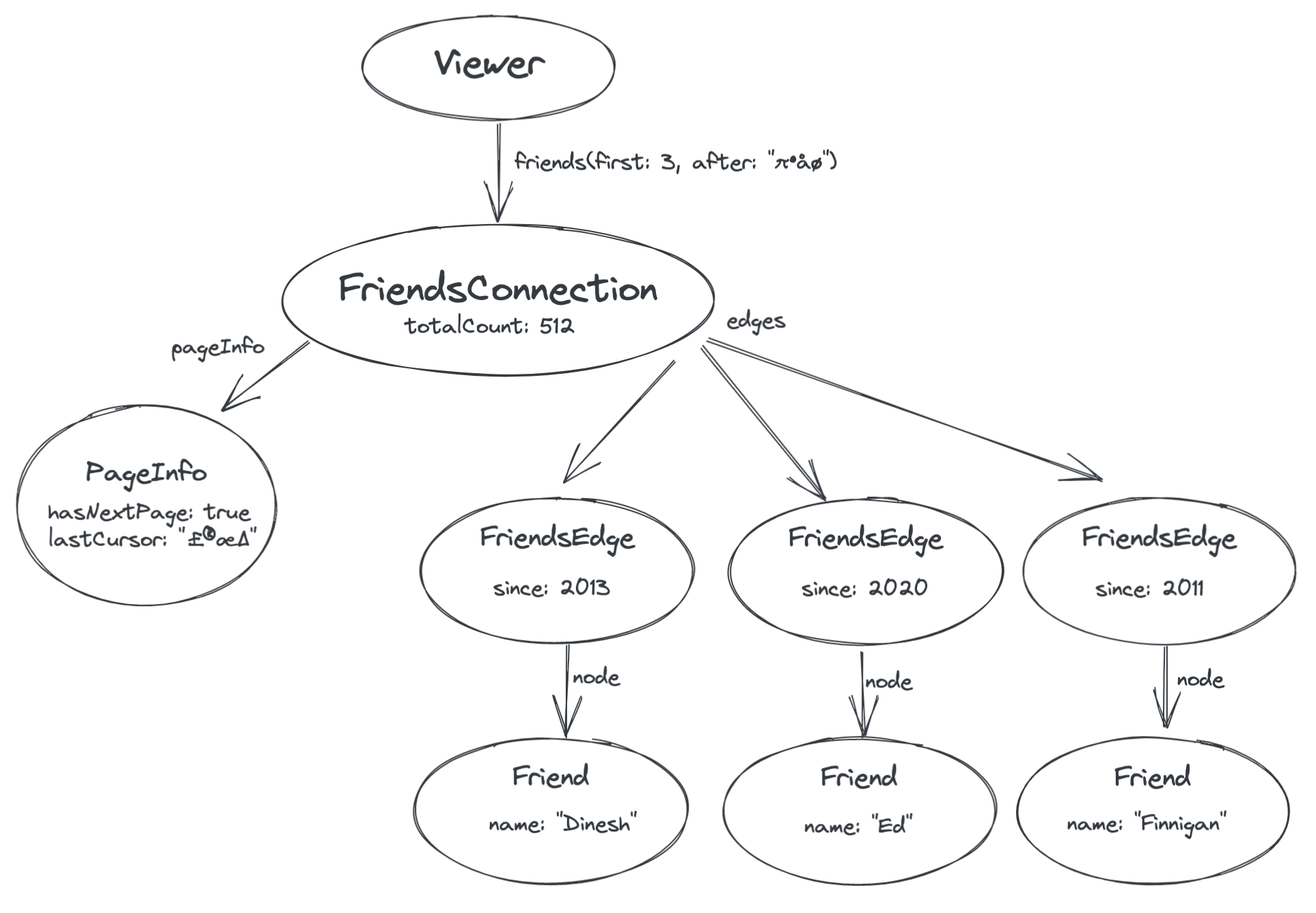
This overall scheme for modeling paginated lists is specified in detail in the GraphQL Cursor Connections Spec. It is flexible for many different applications, and although Relay relies on this convention to handle pagination automatically, designing your schema this way is a good idea whether or not you use Relay.