Elastic Load Balancing (ELB)
Scalability & High Availability
- There are two kinds of scalability
- Vertical Scalability (increasing the size of the instance)
- Horizontal Scalability or Elasticity (increasing the number of instances / systems for your application)
- Scalability is linked but different to High Availability
- High Availability usually goes hand in hand with horizontal scaling
- High availability means running your application / system in at least 2 data centers (== Availability Zones)
- The goal of high availability is to survive a data center loss
- The high availability can be passive (for RDS Multi AZ for example)
- The high availability can be active (for horizontal scaling)
Examples
- Vertical Scaling: Increase instance size (= scale up / down)
- From: t2.nano - 0.5G of RAM, 1 vCPU
- To: u-12tb1.metal – 12.3 TB of RAM, 448 vCPUs
- Horizontal Scaling: Increase number of instances (= scale out / in)
- Auto Scaling Group
- Load Balancer
- High Availability: Run instances for the same application across multi AZ
- Auto Scaling Group multi AZ
- Load Balancer multi AZ
Load Balancing
- Load Balances are servers that forward traffic to multiple servers (e.g., EC2 instances) downstream
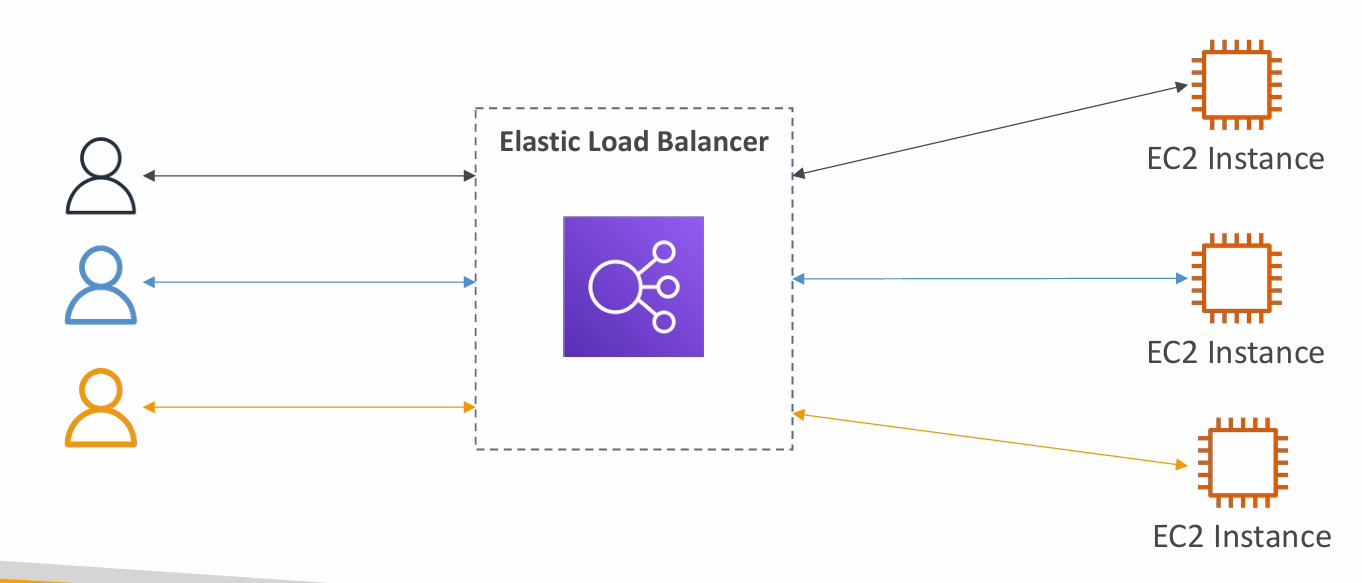
Why use a load balancer?
- Spread load across multiple downstream instances
- Expose a single point of access (DNS) to your application
- Seamlessly handle failures of downstream instances
- Do regular health checks to your instances
- Provide SSL termination (HTTPS) for your websites
- Enforce stickiness with cookies
- High availability across zones
- Separate public traffic from private traffic
Why use an Elastic Load Balancer?
- An Elastic Load Balancer is a managed load balancer
- AWS guarantees that it will be working
- AWS takes care of upgrades, maintenance, high availability
- AWS provides only a few configuration knobs
- It costs less to setup your own load balancer but it will be a lot more effort on your end
- It is integrated with many AWS offerings / services
- EC2, EC2 Auto Scaling Groups, Amazon ECS
- AWS Certificate Manager (ACM), CloudWatch
- Route 53, AWS WAF, AWS Global Accelerator
Health Checks
- Health Checks are crucial for Load Balancers
- They enable the load balancer to know if instances it forwards traffic to are available to reply to requests
- The health check is done on a port and a route (/health is common)
- If the response is not 200 (OK), then the instance is unhealthy

Types of load balancer on AWS
-
Classic Load Balancer (v1)
- HTTP, HTTPS, TCP, SSL (secure TCP)
-
Application Load Balancer (v2)
- HTTP, HTTPS, WebSocket
-
Network Load Balancer (v2)
- TCP, TLS (secure TCP), UDP
-
Gateway Load Balancer (GWLB - newest type of balancer)
- Operates at layer 3 (Network layer) – IP Protocol
-
Overall, it is recommended to use the newer generation load balancers as they provide more features
-
Some load balancers can be setup as internal (private) or external (public) ELBs
Security Groups
CLB - Classic Load Balancers (v1)
- Supports TCP (Layer 4), HTTP & HTTPS (Layer 7)
- Health checks are TCP or HTTP based
- Fixed hostname XXX.region.elb.amazonaws.com
info
Most likely not relevant anymore for exam since its deprecated.
ALB - Application Load Balancer (v2)
- Application load balancers is Layer 7 (HTTP)
- Load balancing to multiple HTTP applications across machines (target groups)
- Load balancing to multiple applications on the same machine (ex: containers)
- Support for HTTP/2 and WebSocket
- Supports redirects (from HTTP to HTTPS for example)
- Routing tables to different target groups:
- Routing based on path in URL (example.com/users & example.com/posts)
- Routing based on hostname in URL (one.example.com & other.example.com)
- Routing based on Query String, Headers (example.com/users?id=123&order=false)
- ALB are a great fit for micro services & container-based application (example: Docker & Amazon ECS)
- Has a port mapping feature to redirect to a dynamic port in ECS
- In comparison, we’d need multiple Classic Load Balancer per application
HTTP Based Traffic
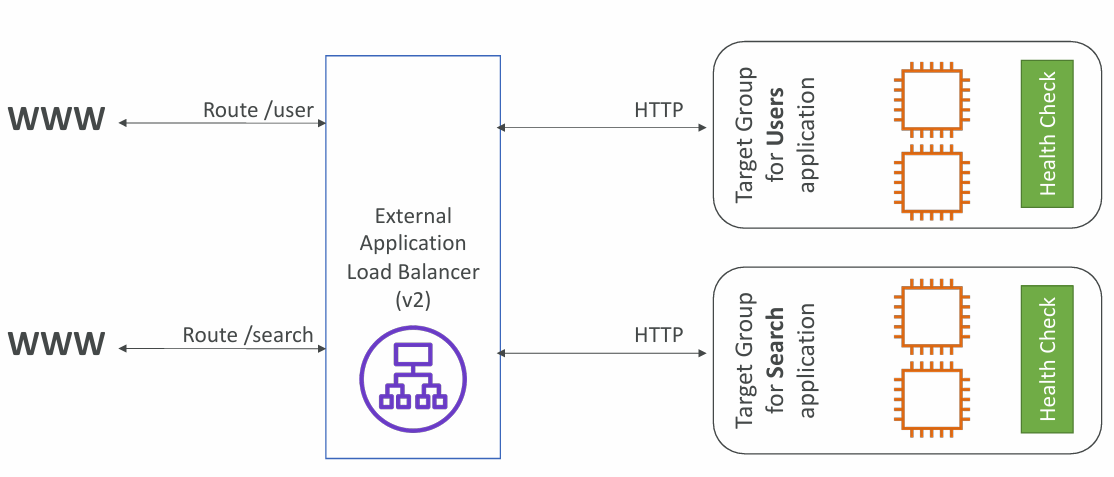
Possible Target Groups
- EC2 instances (can be managed by an Auto Scaling Group) – HTTP
- ECS tasks (managed by ECS itself) – HTTP
- Lambda functions – HTTP request is translated into a JSON event
- IP Addresses �– must be private IPs
ALB can route to multiple target groups. Health checks are at the target group level.
Query Strings/Parameters Routing
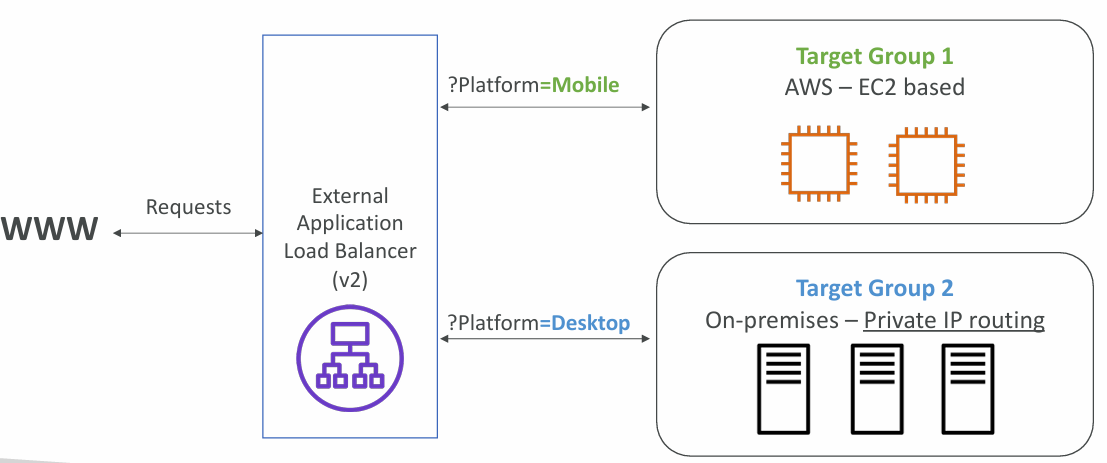
Good to Know
- Fixed hostname (XXX.region.elb.amazonaws.com)
- The application servers don’t see the IP of the client directly
- The true IP of the client is inserted in the header X-Forwarded-For
- We can also get Port (X-Forwarded-Port) and proto (X-Forwarded-Proto)
NLB - Network Load Balancer (v2)
- Network load balancers (Layer 4) allow to:
- Forward TCP & UDP traffic to your instances
- Handle millions of request per seconds
- Ultra-low latency
- NLB has one static IP per AZ, and supports assigning Elastic IP (helpful for whitelisting specific IP)
- NLB are used for extreme performance, TCP or UDP traffic
TCP (Layer 4) Based Traffic
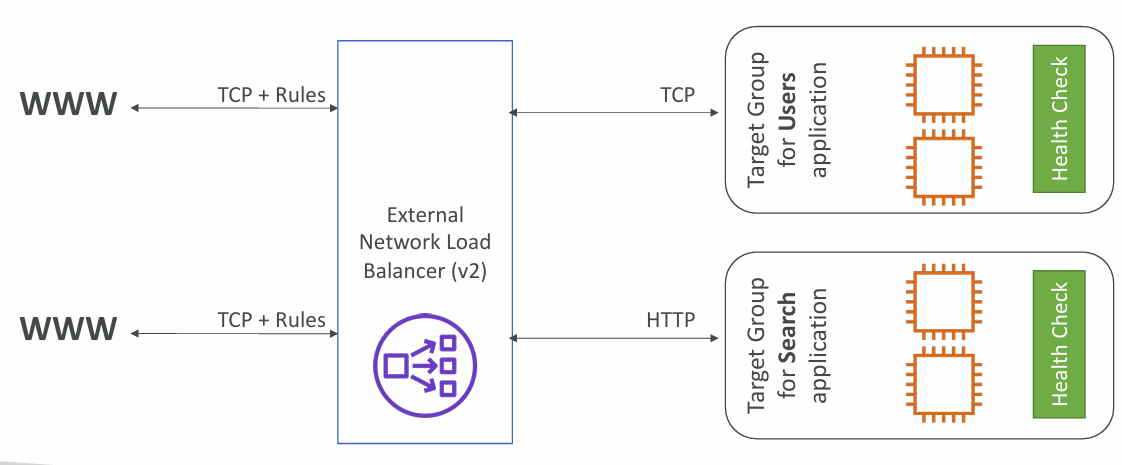
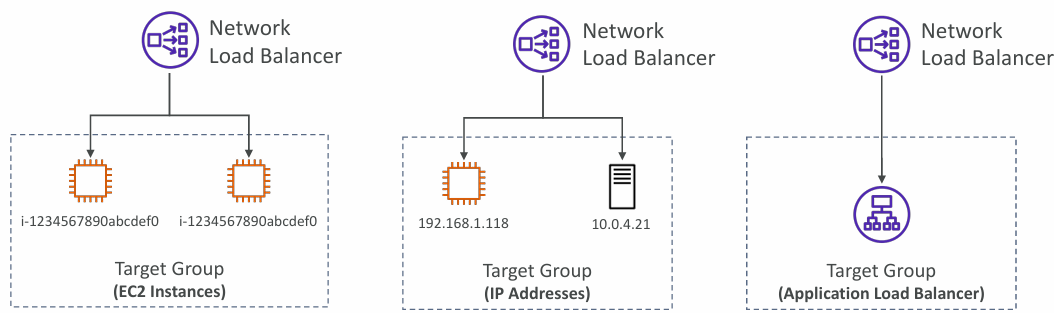
Possible Target Groups
- EC2 instances
- IP Addresses – must be private IPs
- Application Load Balancer
- Health Checks support the TCP, HTTP and HTTPS Protocols
GLB - Gateway Load Balancer
- Deploy, scale, and manage a fleet of 3rd party network virtual appliances in AWS
- Example: Firewalls, Intrusion Detection and Prevention Systems, Deep Packet Inspection Systems, payload manipulation, etc.
- Operates at Layer 3 (Network Layer) – IP Packets
- Combines the following functions:
- Transparent Network Gateway – single entry/exit for all traffic
- Load Balancer – distributes traffic to your virtual appliances
- Uses the GENEVE protocol on port 6081
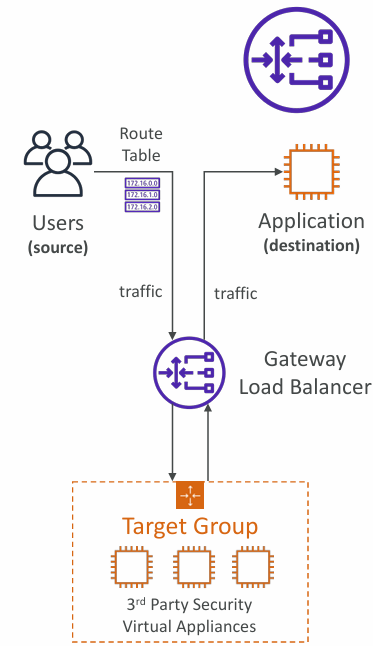
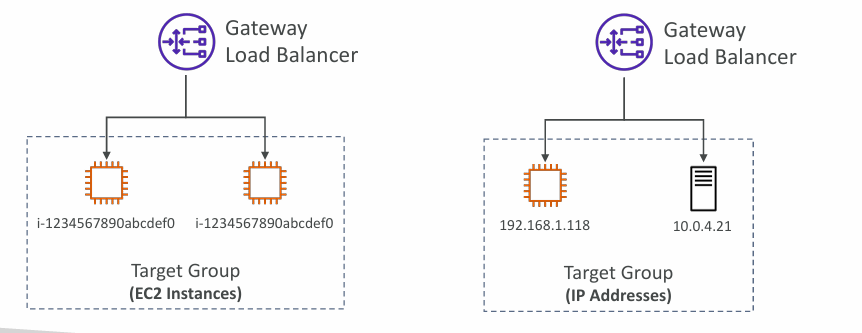
Possible Target Groups
- EC2 instances
- IP Addresses – must be private IPs
Sticky Sessions (Session Affinity)
- Goal: Same client is always redirected to the same instance behind a load balancer
- This works for Classic Load Balancer, Application Load Balancer, and Network Load Balancer
- For both CLB & ALB, the “cookie” used for stickiness has an expiration date you control
- Use case: make sure the user doesn’t lose his session data
- Enabling stickiness may bring imbalance to the load over the backend EC2 instances
Cookie Names
- Application-based Cookies
- Custom cookie
- Generated by the target
- Can include any custom attributes required by the application
- Cookie name must be specified individually for each target group
- Don’t use AWSALB, AWSALBAPP, or AWSALBTG (reserved for use by the ELB)
- Application cookie
- Generated by the load balancer
- Cookie name is AWSALBAPP
- Custom cookie
- Duration-based Cookies
- Cookie generated by the load balancer
- Cookie name is AWSALB for ALB, AWSELB for CLB
info
For exam it is only important to know high level that there are different cookies which are either application-based or duration-based.
Cross-Zone Load Balancing
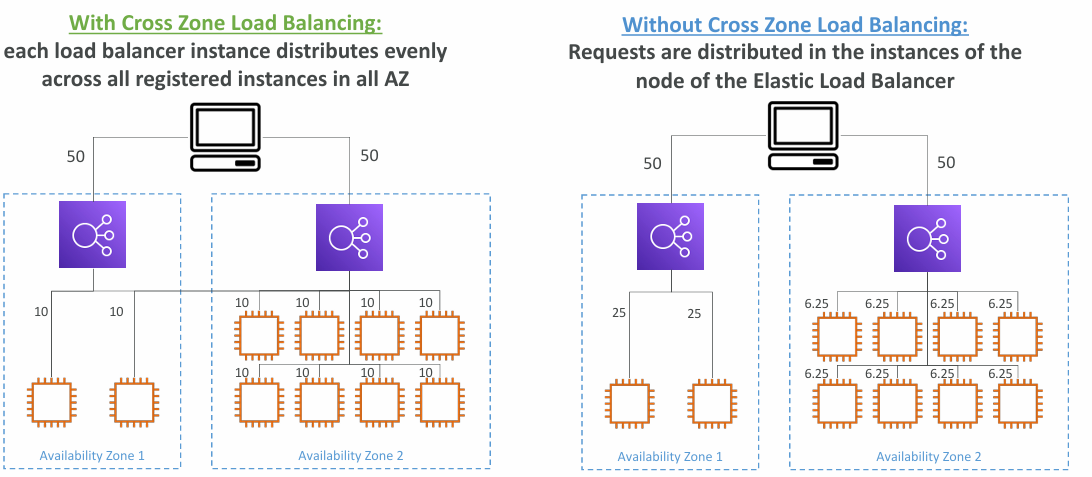
- Application Load Balancer
- Enabled by default (can be disabled at the Target Group level)
- No charges for inter AZ data
- Network Load Balancer & Gateway Load Balancer
- Disabled by default
- You pay charges ($) for inter AZ data if enabled
- Classic Load Balancer
- Disabled by default
- No charges for inter AZ data if enabled
SSL Certificates

- The load balancer uses an X.509 certificate (SSL/TLS server certificate)
- You can manage cer tificates using ACM (AWS Certificate Manager)
- You can create upload your own certificates alternatively
- HTTPS listener:
- You must specify a default cer tificate
- You can add an optional list of cer ts to suppor t multiple domains
- Clients can use SNI (Server Name Indication) to specify the hostname they reach
- Ability to specify a security policy to support older versions of SSL / TLS (legacy clients)
Server Name Indication (SNI)
- SNI solves the problem of loading multiple SSL certificates onto one web server (to serve multiple websites)
- Only works for ALB & NLB (newer generation), CloudFront
- Does not work for CLB (older gen)
- It’s a “newer” protocol, and requires the client to indicate the hostname of the target server in the initial SSL handshake
- The server will then find the correct certificate, or return the default one
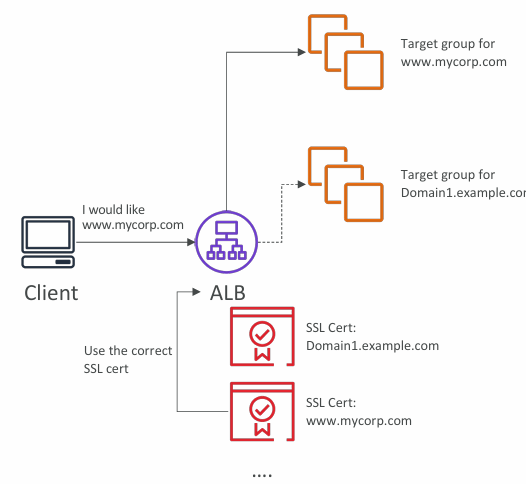
SSL Certs by Load Balancer
- Classic Load Balancer (v1)
- Support only one SSL certificate
- Must use multiple CLB for multiple hostname with multiple SSL certificates
- Application Load Balancer (v2)
- Supports multiple listeners with multiple SSL certificates
- Uses Server Name Indication (SNI) to make it work
- Network Load Balancer (v2)
- Supports multiple listeners with multiple SSL certificates
- Uses Server Name Indication (SNI) to make it work
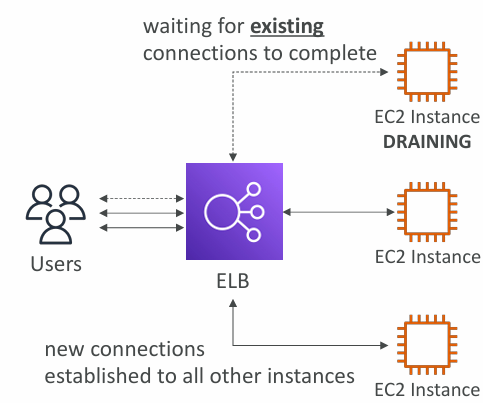
Connection Draining
- Feature is named Connection Draining for CLB or Deregistration Delay – for ALB & NLB
- Time to complete “in-flight requests” while the instance is de-registering or unhealthy
- Stops sending new requests to the EC2 instance which is de-registering
- Between 1 to 3600 seconds (default: 300 seconds)
- Can be disabled (set value to 0)
- Set to a low value if your requests are short
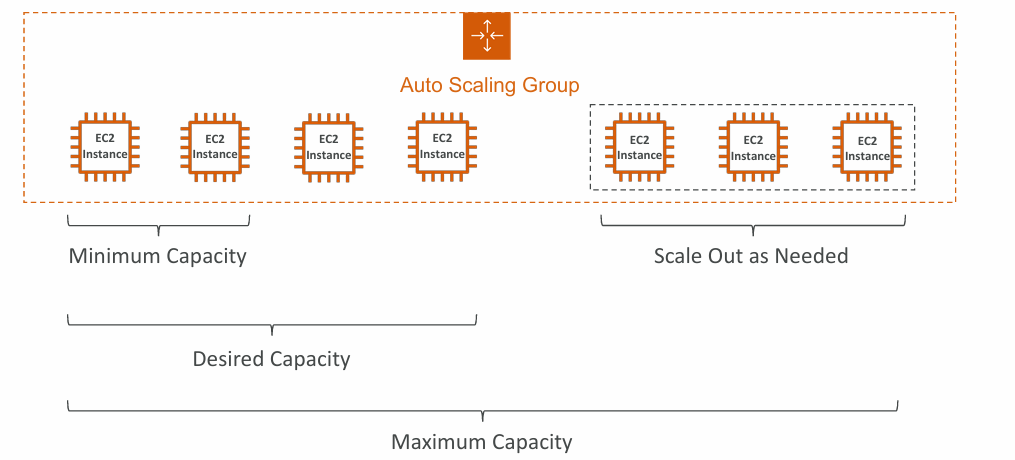
Auto Scaling Groups
The goal of an Auto Scaling Group (ASG) is to:
- Scale out (add EC2 instances) to match an increased load
- Scale in (remove EC2 instances) to match a decreased load
- Ensure we have a minimum and a maximum number of EC2 instances running
- Automatically register new instances to a load balancer
- Re-create an EC2 instance in case a previous one is terminated (ex: if unhealthy)
ASG are free (you only pay for the underlying EC2 instances).
Auto Scaling Group with Load Balancer:
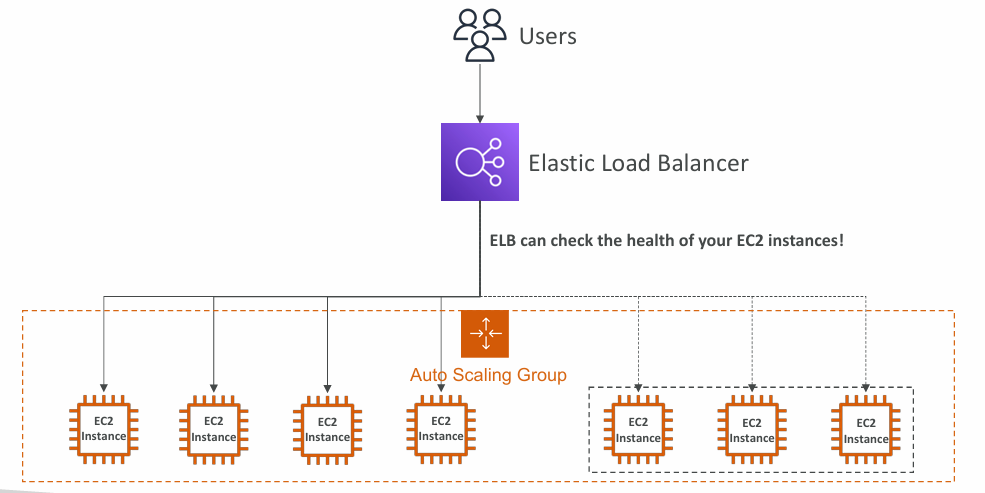
Attributes
- A Launch Template
- AMI + Instance Type
- EC2 User Data
- EBS Volumes
- Security Groups
- SSH Key Pair
- IAM Roles for your EC2 Instances
- Network + Subnets Information
- Load Balancer Information
- Min Size / Max Size / Initial Capacity
- Scaling Policies

CloudWatch Alarms & Scaling
- It is possible to scale an ASG based on CloudWatch alarms
- An alarm monitors a metric (such as Average CPU, or a custom metric)
- Metrics such as Average CPU are computed for the overall ASG instances
- Based on the alarm:
- We can create scale-out policies (increase the number of instances)
- We can create scale-in policies (decrease the number of instances)

Scaling Policies
- Dynamic Scaling
- Target Tracking Scaling
- Simple to set-up
- Example: I want the average ASG CPU to stay at around 40%
- Simple / Step Scaling
- When a CloudWatch alarm is triggered (example CPU > 70%), then add 2 units
- When a CloudWatch alarm is triggered (example CPU < 30%), then remove 1
- Target Tracking Scaling
- Scheduled Scaling
- Anticipate a scaling based on known usage patterns
- Example: increase the min capacity to 10 at 5 pm on Fridays
- Predictive scaling: continuously forecast load and schedule scaling ahead
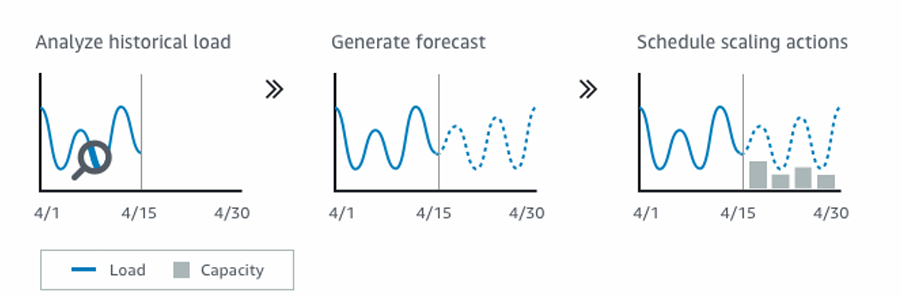
Good metrics to scale on
- CPUUtilization: Average CPU utilization across your instances
- RequestCountPerTarget: to make sure the number of requests per EC2 instances is stable
- Average Network In / Out (if you’re application is network bound)
- Any custom metric (that you push using CloudWatch)
Scaling Cooldowns
- After a scaling activity happens, you are in the cooldown period (default 300 seconds)
- During the cooldown period, the ASG will not launch or terminate additional instances (to allow for metrics to stabilize)
- Advice: Use a ready-to-use AMI to reduce configuration time in order to be serving request faster and reduce the cooldown period
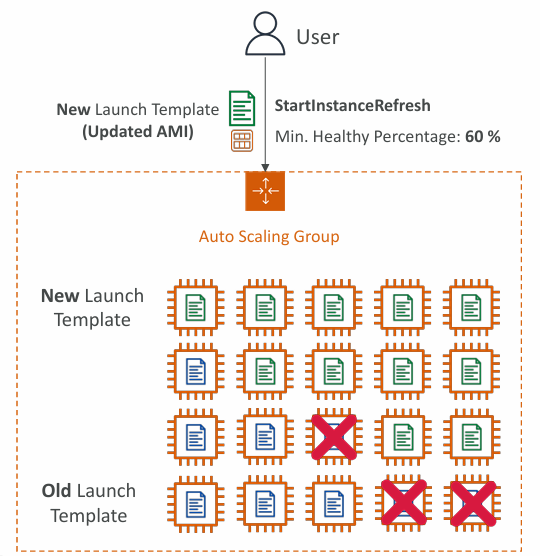
Instance Refresh
- Goal: update all EC2 instances based on new launch template
- Setting of minimum healthy percentage (percentage which will remain up during refresh)
- Specify warm-up time (how long until the instance is ready to use)